[홈서버] 자꾸 터지는 Next.js 서버, k3s로 모니터링 시스템 구축하기
프론트엔드 개발자의 좌충우돌 홈서버 k3s 구축기. Next.js 서버 장애를 계기로 Prometheus와 Grafana 모니터링 시스템을 직접 만들어봅니다.
이 글은 제 개인 프로젝트 서버가 주기적으로 멈추는 작은 문제에서 시작해, 홈서버에 경량 쿠버네티스(k3s)와 모니터링 시스템을 구축하게 된 전체 여정을 담은 기록입니다. 저처럼 인프라에 익숙하지 않은 분들도 따라오실 수 있도록 최대한 자세히 풀어보려 합니다.
”서버 또 죽었습니다.”
최근 운영 중인 Next.js 블로그 서버가 자꾸만 멈췄습니다. 원인은 이미지 최적화에 사용되는 sharp 라이브러리와의 충돌로 추정됐죠.
ImageError: Unable to optimize image and unable to fallback to upstream image
at imageOptimizer (.../next/dist/server/image-optimizer.js:688:19)서버가 멈출 때마다 SSH로 접속해 pnpm dev 명령어를 다시 실행하는 일은 여간 귀찮은 게 아니었습니다. 물론 pm2 같은 프로세스 매니저를 쓰면 돼요. Docker에 띄워도 프로세스를 항상 다시 실행해주기 때문에 서버가 죽으면 자동으로 다시 실행되어 문제를 해결할 수 있어요.
저는 이 기회에 pm2보다는 평소 궁금했던 쿠버네티스(k8s) 기반의 모니터링 시스템을 직접 구축해보기로 결심했습니다.
어차피 놀고 있는 홈서버도 있었기 때문이죠.
최종 목표: 내 Next.js 앱이 살아있는지 30초마다 확인하고, 문제가 생기면 바로 알 수 있는 시스템을 만들자.
초보자를 위한 핵심 개념 정리
이 과정에서 저를 혼란스럽게 했던 쿠버네티스와 프로메테우스의 핵심 용어들을 정리했어요.
쿠버네티스 기본 용어
| 용어 | 한 줄 요약 |
|---|---|
| Pod | 컨테이너 1~N개를 같이 관리하는 쿠버네티스 최소 실행 단위 |
| Deployment | ”원하는 Pod 개수와 버전”을 유지·배포하는 복제본 관리자 |
| Service | 여러 Pod에 하나의 고정된 주소를 부여하는 가상 네트워크 |
| k3s | 아주 작고 가벼운 쿠버네티스. 홈서버처럼 제한된 환경에 딱 좋아요. |
| Helm | 쿠버네티스 앱을 쉽게 설치하고 관리하게 해주는 패키지 매니저 |
모니터링 시스템의 동작 흐름
Probe(스펙): “30초마다 Next.js 앱에 HTTP 요청 보내” 라고 적힌 스펙이에요.Prometheus(관리자): Probe를 보고, 30초마다Blackbox Exporter에게 일을 위임해요.Blackbox Exporter(실행자): 실제로 Next.js 앱에 요청을 보내고 결과를 보고해요.Prometheus(관리자): 보고받은 결과를probe_success 1,probe_duration_seconds 0.2와 같이 숫자로 차곡차곡 저장해요.Grafana(시각화 도구): 저장된 숫자들을 가져와 시각화해요.
실패한 첫 시도, Ingress에 대해 모르겠다.
처음엔 쿠버네티스의 표준 방식인 Ingress를 사용해 외부 트래픽을 서비스에 연결하려고 했었어요.
- K3s 클러스터 설치: 홈서버(Ubuntu)에 경량 쿠버네티스인 K3s를 설치했습니다.
- 모니터링 스택 설치: Helm을 이용해 Prometheus와 Grafana를 설치했습니다.
helm install lightweight-monitoring prometheus-community/kube-prometheus-stack -n monitoring - Grafana Ingress 설정: 외부에서
https://mj-dev.site/grafana로 접근할 수 있도록 Ingress 설정을 추가했습니다.
하지만 여기서 두 가지 큰 문제에 부딪혔습니다.
- 🚨 Fake SSL Certificate: Ingress가
Fake SSL Certificate를 발급해 브라우저에서 보안 경고가 발생했습니다. - 🚨 경로 충돌: Grafana가
/grafana뿐만 아니라 루트 경로(/)까지 점유하면서, 기존 Next.js 앱과 충돌했습니다.
Ingress가 뭐죠?
Ingress는 클러스터 외부 요청을 내부 서비스로 연결하는 라우터에요. 여러 서비스를 운영할 때 도메인이나 경로에 따라 트래픽을 나누거나, TLS 인증서 관리를 자동화하는 등 강력한 기능을 제공하죠.
| 항목 | Ingress | Nginx 직접 설정 |
|---|---|---|
| 쿠버네티스 통합 | ✅ 리소스로 관리 (kubectl apply) | ❌ 외부에서 수동 관리 |
| TLS 자동화 | ✅ Cert Manager 등과 연동 | ❌ 수동으로 certbot 관리 |
| 유연한 라우팅 | ✅ Path/Host 기반 라우팅 | ⚠️ 직접 설정 필요 |
장기적으로 여러 서비스를 운영한다면 Ingress가 정답이지만, 지금 당장 저에겐 Nginx를 직접 설정하는 방식이 더 간단하고 확실한 해결책이었습니다.
Nginx 직접 프록시로 방향 전환
결국 Ingress를 포기하고, 익숙한 Nginx로 직접 리버스 프록시를 구성하는 방향으로 결정했어요.
- Ingress의 인증서 문제를 해결하기엔 너무 복잡해 보였어요.
- 경로 충돌은 nginx로도 해결할 수 있을 것 같았어요.
그래서 이번 프로젝트에서는 Nginx를 직접 설정하는 방향으로 결정했어요.
1. Ingress 비활성화
Helm 설정에서 Ingress를 꺼줍니다.
helm upgrade lightweight-monitoring \
-n monitoring \
--set grafana.ingress.enabled=false2. Grafana 서브패스 설정
Grafana가 /grafana 경로에서 올바르게 동작하려면, 자신이 어떤 주소로 서비스되는지 알려줘야 합니다.
# Helm 업그레이드 시 다음 옵션 추가
--set grafana.env.GF_SERVER_ROOT_URL="https://mj-dev.site/grafana" \
--set grafana.extraArgs[0]="--serve-from-subpath"3. kubectl 포트포워딩 자동화
Grafana는 클러스터 내부에서만 접근 가능하므로, 외부에서 접근할 수 있는 통로가 필요해요. kubectl port-forward 명령어가 그 역할을 하지만, 터미널을 끄거나 서버가 재부팅되면 끊어집니다.
이 문제를 해결하기 위해 systemd 서비스로 등록하여 이 명령이 항상 실행되도록 만들었어요.
/etc/systemd/system/grafana-portforward.service
[Unit]
Description=Port forward for Grafana service
[Service]
ExecStart=/usr/local/bin/kubectl port-forward -n monitoring svc/lightweight-monitoring-grafana 3100:80
User=mj
Environment="KUBECONFIG=/home/mj/.kube/config"
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target이제 Grafana 서비스는 제 로컬 서버의 3100 포트에서 항상 접근 가능해요.
4. Nginx 리버스 프록시 구성
마지막으로 Nginx가 경로에 따라 요청을 분배하도록 설정합니다. /etc/nginx/sites-available/default
server {
# ... (SSL 및 서버 이름 설정)
location / {
# 루트 경로는 Next.js 앱으로 (pm2로 실행 중)
proxy_pass http://127.0.0.1:3000;
proxy_set_header Host $host;
# ... (기타 헤더 설정)
}
location /grafana/ {
# /grafana/ 경로는 systemd로 열어둔 Grafana 포트로
proxy_pass http://127.0.0.1:3100/;
proxy_set_header Host $host;
}
}이제 https://mj-dev.site는 Next.js 앱을, https://mj-dev.site/grafana는 Grafana 대시보드를 정상적으로 보여줄 수 있게 되었어요.
Next.js 앱 모니터링하기
이제 인프라는 준비됐으니, 원래 목표였던 Next.js 헬스체크를 구현할 차례에요.
1. Next.js 앱을 Kubernetes에 올리기
먼저, Next.js 앱을 Docker 이미지로 만들고 k3s 클러스터 내부 이미지 저장소에 등록했습니다. (docker save → k3s ctr images import)
그리고 다음과 같은 Deployment와 Service YAML 파일을 작성하여 앱을 배포했습니다.
k8s/blog.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nextjs-app-deployment
spec:
replicas: 1
template:
spec:
containers:
- name: nextjs-app
image: nextjs-app:latest # 로컬에 임포트한 이미지
imagePullPolicy: Never # 로컬 이미지만 사용
ports:
- containerPort: 3000
command: ['pnpm', 'start'] # dev가 아닌 start로 실행
---
apiVersion: v1
kind: Service
metadata:
name: nextjs-app-service
spec:
selector:
app: nextjs-app
ports:
- protocol: TCP
port: 3000
targetPort: 3000이로써 클러스터 내부에서 nextjs-app-service.default.svc.cluster.local:3000 주소로 접근할 수 있는 앱이 생겼습니다.
2. Blackbox Exporter로 Observing
여기서는 Blackbox Exporter라는 도구를 사용합니다. 이 도구는 마치 외부 사용자처럼 지정된 URL에 HTTP 요청을 보내고, 그 결과를(성공 여부, 응답 시간 등) Prometheus가 수집할 수 있는 숫자 데이터(메트릭)로 바꿔줘요.
-
Blackbox Exporter 설치: Helm으로 간단하게 설치했습니다.
helm install blackbox prometheus-community/prometheus-blackbox-exporter -n monitoring -
Probe 리소스 생성: “누가, 어디를, 얼마나 자주” 검사할지 정의하는
Probe리소스를 만듭니다.probe.yaml
apiVersion: monitoring.coreos.com/v1 kind: Probe metadata: name: nextjs-http namespace: monitoring labels: # Prometheus가 이 라벨을 보고 자동으로 타겟으로 인식합니다. release: lightweight-monitoring spec: interval: 30s module: http_2xx # HTTP 200번대 응답이면 성공 prober: # blackbox exporter 서비스 주소 url: blackbox-prometheus-blackbox-exporter.monitoring.svc:9115 targets: staticConfig: static: # 검사할 대상: k8s에 배포한 Next.js 서비스의 내부 주소 - http://nextjs-app-service.default.svc.cluster.local:3000이 YAML 파일을
kubectl apply -f probe.yaml로 적용하면, 30초마다 Blackbox Exporter가 제 Next.js 앱에 HTTP 요청을 보내기 시작합니다.
3. Grafana에서 결과 확인
Grafana의 Explore 메뉴에서 데이터 소스를 Prometheus로 선택하고, 다음 쿼리를 입력합니다.
probe_success{probe="nextjs-http"}: 성공하면1, 실패하면0을 반환합니다.probe_duration_seconds{probe="nextjs-http"}: 요청에 걸린 전체 시간을 보여줍니다.
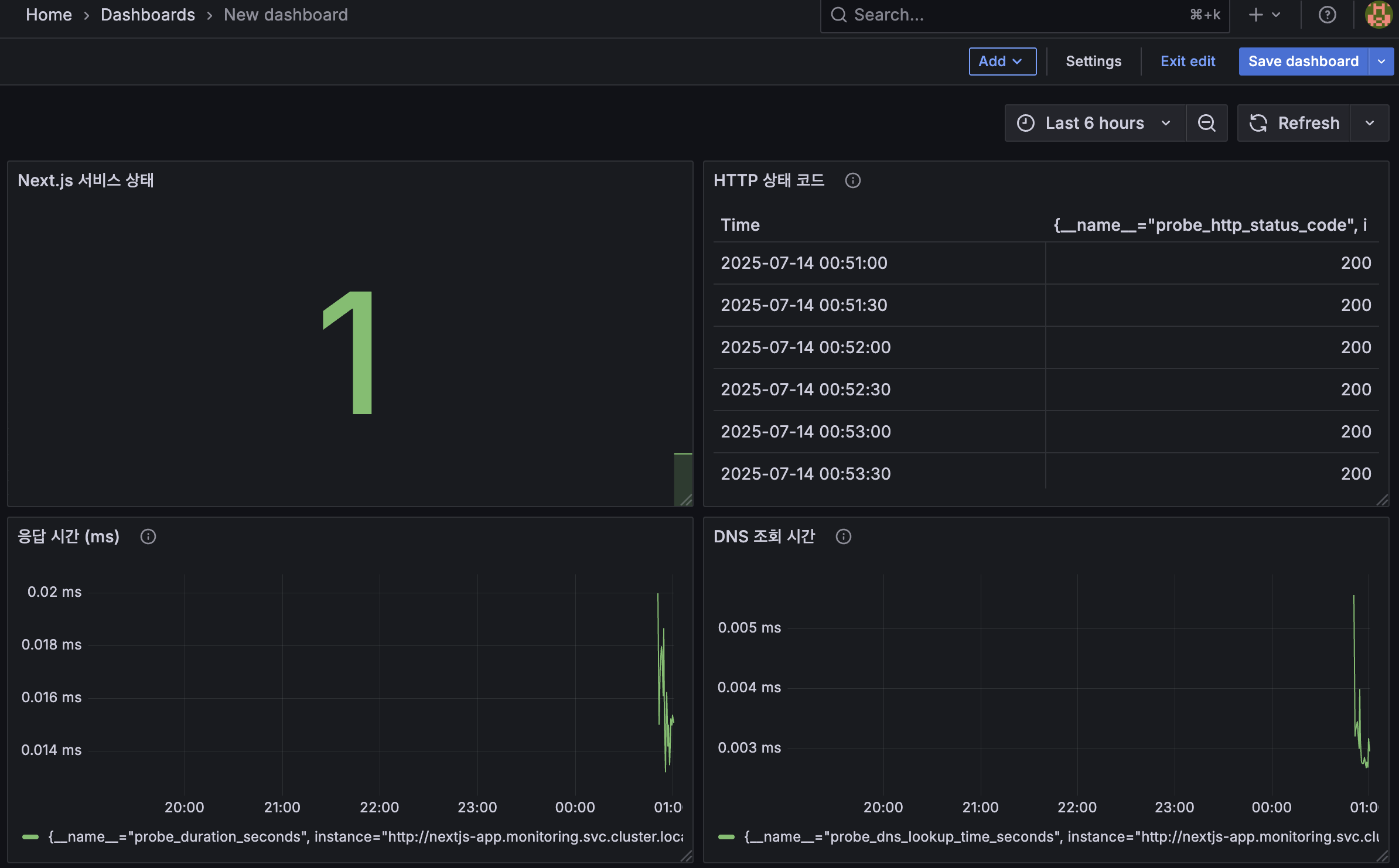
이제 제 Next.js 서버가 응답이 없으면 probe_success 그래프가 0으로 뚝 떨어지고, 저는 이 값에 알람을 걸어 장애를 즉시 인지할 수 있게 되었습니다.
그리고 도커는 프로세스를 항상 다시 실행해주기 때문에 서버가 죽으면 자동으로 다시 실행되어 문제를 해결할 수 있어요.
DevOps 개발자를 리스펙하며
단순히 ‘서버가 죽는다’는 문제에서 시작했지만, K3s, Nginx, Prometheus, Grafana를 직접 다루며 전체 시스템이 어떻게 상호작용하는지 몸으로 배울 수 있었던 값진 경험이었어요. 이번 기회에 DevOps 개발자분들이 얼마나 복잡하고 다양한 기술 스택을 다루는지, 그리고 안정적인 서비스 운영을 위해 얼마나 많은 고민과 노력을 하는지 제대로 느낄 수 있었습니다. 제 작은 문제 해결 과정에서도 수많은 시행착오가 있었는데, 대규모 서비스를 운영하는 분들의 노고에 진심으로 존경을 표합니다.
여러분도 이번 기회에 한 번 도전해보시는 건 어떨까요? 생각보다 훨씬 재미있고 많은 것을 배울 수 있을 거에요. 읽어주셔서 감사합니다.