- Published on
[OSSCA] State-based CRDT에 대해 알아보기
- Authors

- Name
- MJ
CRDT에서는 Operation-based와 State-based 두 방식을 사용하여 데이터 일관성(data consistency)을 유지합니다.
Yorkie에서는 Operation-based CRDT를 채택해서 데이터 일관성을 유지합니다.
Operation-based CRDT 외에는 State-based CRDT가 있습니다. 이번 글에서는 Stated-based가 Operation-based와 어떻게 다른지, 어떤 장단점이 있는지 알아보겠습니다.
State-based CRDT에 대하여
State-based CRDT는 전체 상태를 전송하고, 수신한 상태를 병합하는 방식입니다. 병합 함수는 교환 가능, 결합 가능, 그리고 멱등성이 있어야 합니다.
- 결합성(Associativity): (A ∪ B) ∪ C = A ∪ (B ∪ C)
- 교환성(Commutativity): A ∪ B = B ∪ A
- 멱등성(Idempotency): A ∪ A = A
- 단조성(Monotonicity): A ≤ A ∪ B
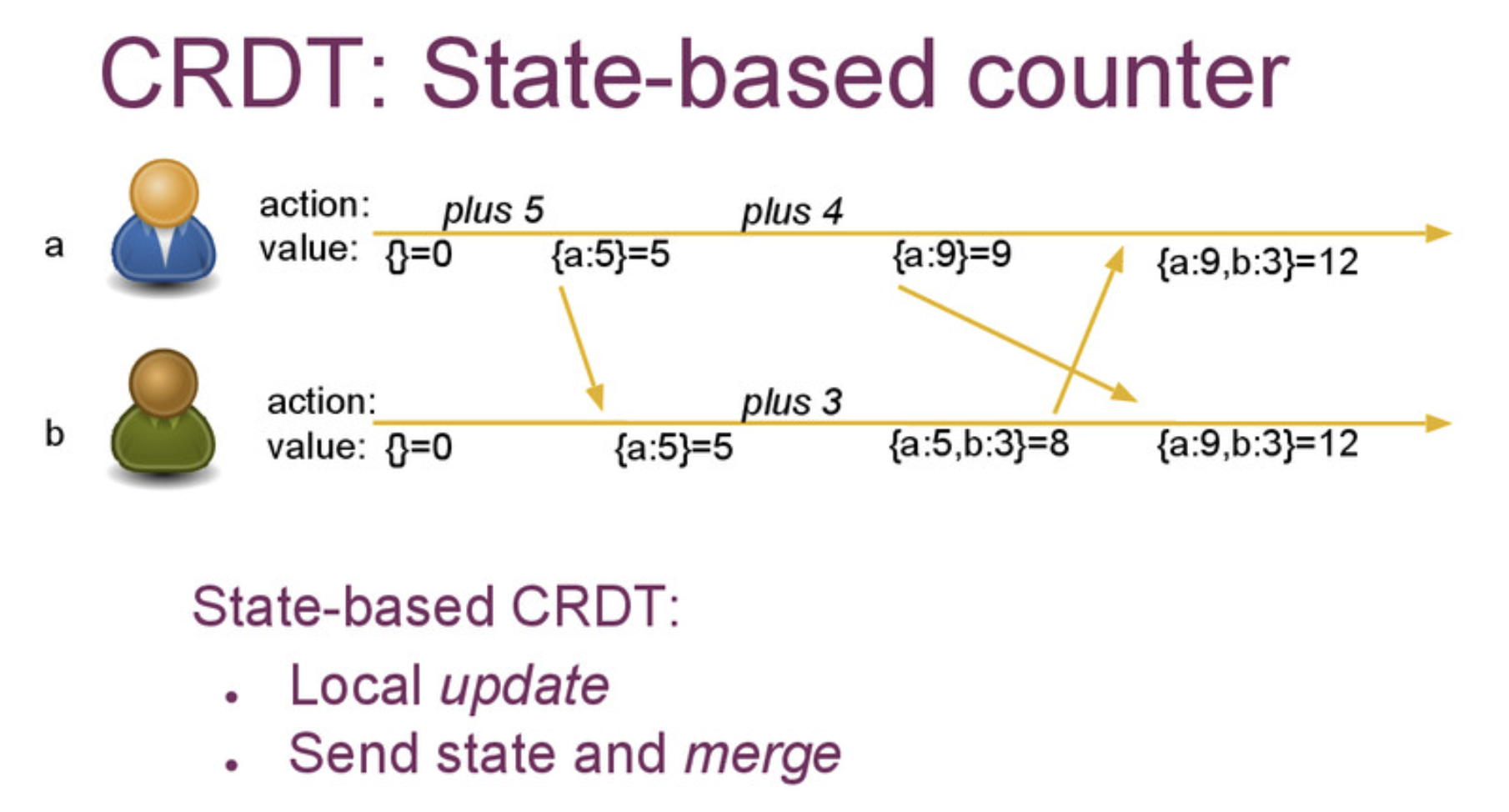
이미지 예시를 보면, 각 클라이언트는 자신의 상태를 다른 클라이언트에게 전송하고, 수신한 상태를 병합합니다.
a의 상태와 b의 상태를 가지고 있고, 최종 결과는 a ∪ b가 됩니다.
단순히 전체 상태를 전송하고 병합 한다고 생각할 수 있지만 데이터의 일관성을 유지하기 위해서 State-based CRDT는 아래와 같은 규칙을 지킵니다.
상태 기반 동기화
각 노드는 자신의 전체 데이터 상태를 메모리나 저장소에 유지합니다.
type State = {
data: Map<string, number>;
};
동기화 시점에 전체 상태를 직렬화(예: JSON, Protocol Buffers)하여 다른 노드로 전송합니다. 수신 노드는 받은 상태를 자신의 상태와 병합합니다.
const stateA: State = {
data: new Map([['a', 1], ['b', 2]]),
};
const stateB: State = {
data: new Map([['b', 3], ['c', 4]]),
};
const mergedState = merge(stateA, stateB);
// mergedState.data = Map([['a', 1], ['b', 3], ['c', 4]]);
function merge(stateA: State, stateB: State): State {
const mergedData = new Map([...stateA.data, ...stateB.data]);
return { data: mergedData };
}
부분 순서 관계
CRDT는 부분 순서 관계를 유지합니다.
부분 순서 관계란, 두 상태를 비교했을 때 두 상태가 동일하거나, 한 상태가 다른 상태보다 먼저 적용되었음을 알 수 있습니다.
이를 통해 동시 업데이트 시나리오에서도 데이터 일관성을 유지할 수 있습니다.
type NodeId = string;
class VectorClock {
constructor(private clock: Map<NodeId, number> = new Map()) {}
// increment, merge, compare 로직
// compare은 vector clock을 비교함
}
class StateCRDT<T> {
private state: Map<string, { value: T; clock: VectorClock }> = new Map();
private vectorClock: VectorClock = new VectorClock();
constructor(private nodeId: NodeId) {}
// get, set, merge 로직
// merge시 VectorClock을 사용하여 부분 순서 관계를 유지
}
// 사용 예시
const node1 = new StateCRDT<string>('node1');
const node2 = new StateCRDT<string>('node2');
node1.set('key1', 'value1');
node2.set('key2', 'value2');
// 노드 간 상태 교환 및 병합
node1.merge(node2);
node2.merge(node1);
// 병합시 충돌이 없는 경우
console.log(node1.get('key1'), node1.get('key2')); // 'value1', 'value2'
console.log(node2.get('key1'), node2.get('key2')); // 'value1', 'value2'
// 동시 업데이트 시나리오
node1.set('key3', 'value3 from node1');
node2.set('key3', 'value3 from node2');
node1.merge(node2);
node2.merge(node1);
// 병합시 충돌이 있는 경우
// vector clock 비교시 마지막 쓰기 승리 전략으로 인해 노드 ID가 더 큰 쪽의 값이 유지됨
console.log(node1.get('key3')); // 'value3 from node2'
console.log(node2.get('key3')); // 'value3 from node2'
예시에서 vector clock을 사용했습니다. vector clock에 대해서 wikipedia에 자세히 설명돼있습니다.
vector clock은 분산 시스템에서 발생한 이벤트의 순서를 추적하는 데 사용됩니다. 각 프로세스는 자신의 vector clock을 유지하고, 이벤트가 발생할 때마다 vector clock을 증가시킵니다. 두 vector clock을 비교하여 어떤 이벤트가 먼저 발생했는지 알 수 있습니다.
vector clock을 통해 부분 순서 관계를 유지하고, 동시 업데이트 시나리오에서도 데이터 일관성을 유지할 수 있습니다.
격자 구조(Lattice)로 이해해보기
{A,B,C}
/ | \
{A,B} {A,C} {B,C}
/ \ / \ / \
{A} {B} {C}
\ | /
{}
격자 구조(Lattice)를 생각해보면 최종적으로 하나의 상태로 수렴하는 것을 알 수 있습니다. 각 클라이언트에 변경사항이 있을 때 순서 무관하게 어떤 순서로 병합하더라도 결과는 동일합니다. (예: LUB(LUB({A}, {C}), {B}) = {A,B,C})
이렇게 격자구조로 병합한다고 생각하면, 네트워크 끊김과 같은 문제가 있어도 데이터 일관성을 유지할 수 있음을 알 수 있습니다.
Q) 데이터가 끊겨도 어떻게 격자 구조를 유지할 수 있을까요?
A) CRDT는 네트워크 끊김 시, 자신의 상태를 유지하고 있습니다. 네트워크가 복구되면 다른 노드와 상태를 병합합니다. 이때, CRDT는 부분 순서 관계를 유지하고 있기 때문에, 병합 시에도 데이터 일관성을 유지할 수 있습니다.
기억하기
부분 순서
주로 개별 이벤트나 작업 간의 인과 관계를 추적합니다. "어떤 이벤트가 다른 이벤트보다 먼저 발생했는가?"를 결정합니다.
격자 구조 전체 시스템 상태의 관계를 정의합니다 서로 다른 (가능하게는 충돌하는) 상태들을 어떻게 일관되게 병합할지 정의합니다.
State-based CRDT 정리
- 전체 상태를 전송하고, 수신한 상태를 병합하는 방식
- 결합성, 교환성, 멱등성, 단조성을 만족해야 함
- 부분 순서 관계를 유지하여 동시 업데이트 시나리오에서도 데이터 일관성을 유지
State-based CRDT는 수렴 상태를 보장하기 쉽고, 네트워크 파티션에도 강합니다.
하지만, 전체 상태를 주고 받기 때문에 오버헤드가 크고 메모리 사용량이 높을 수 있습니다.
다음 글에서는 Operation-based CRDT에 대해 알아보겠습니다.